1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
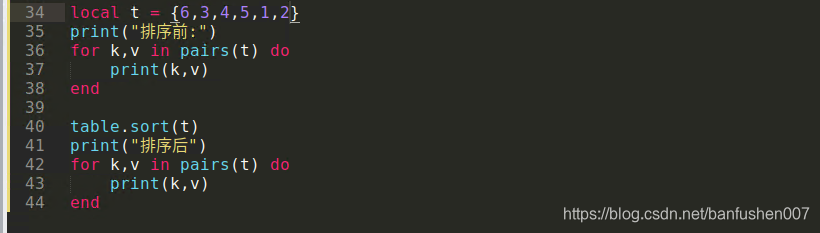
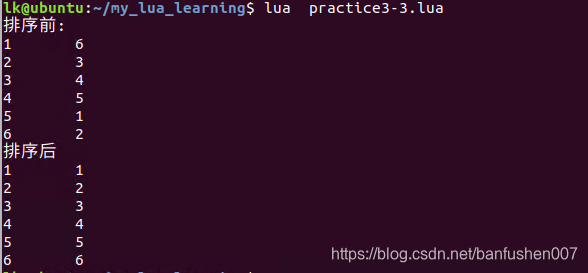
34
35
36
37
38
39
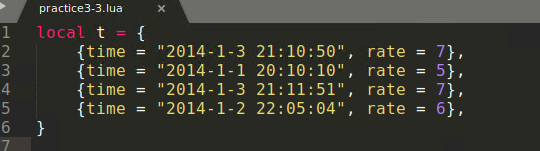
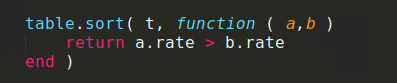
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
| #coding:utf-8
from PIL import Image, ImageChops
import os
import numpy
import random
import numpy as np
import tensorflow as tf
from tensorflow import keras
def read_sample(file_path):
ret = numpy.zeros((32, 32)) #使用numpy构建32*32的数组
im = Image.open(file_path)
rgb_im = im.convert('RGB') #将打开的image指定真彩色模式
for i in range(32):
for j in range(32):
r, g, b = rgb_im.getpixel((i, j)) #读取每个点的r,g,b
average = (r + b + g)/3
if average >= 127: #因为是黑白图像,非黑即白rgb三原色综合是255,所以可以使用127来区分
ret[i, j] = 0
else:
ret[i, j] = 1
return ret
def read_trainset_and_validateset():
trainset_samples = [] #定义训练集
validateset_samples = [] #定义校验集
for i in range(10):
for root, dirs, files in os.walk("out/"+str(i), topdown=False):
for name in files:
pic_path = os.path.join(root, name)
rand_num = random.random()
if rand_num > 0.9: #90%为训练集,剩下10%为校验集
trainset_samples.append( (read_sample(pic_path), i) ) #插入训练集,内容为 (图像内容,数字)
else:
validateset_samples.append( (read_sample(pic_path), i) ) #插入校验集,内容为 (图像内容,数字)
return (trainset_samples, validateset_samples)
# ret = read_sample("C:/Users/bfs/Desktop/learning_ai/0/0_1.png")
# for j in range(32):
# for i in range(32):
# print(int(ret[i, j]), end=' ')
# print('')
#
def train():
print("loading....")
trainset_samples, valideteset_samples = read_trainset_and_validateset() #获取训练集和校验集
x = numpy.zeros((len(trainset_samples), 32, 32, 1)) #构建训练集, 10个32*32的1通道神经元输入
y = numpy.zeros((len(trainset_samples), 10)) #构建训练集, 二维0-9的神经元输出
validate_x = numpy.zeros((len(valideteset_samples), 32, 32, 1)) #构建校验集, 10个32*32的1通道神经元输入
validate_y = numpy.zeros((len(valideteset_samples), 10)) #构建校验集, 二维0-9的神经元输出
print("conver......")
for i in range(len(trainset_samples)):
sample, sample_out = trainset_samples[i] #sample对应读取的图像结果, sample_out对应结果为哪个数字
for xi in range(32):
for yi in range(32):
x[i, xi, yi, 0] = sample[xi, yi] #训练集输入, i对应目前是哪个神经元的输入, sample为读取图像的结果
y[i, sample_out] = 1 #训练集输出, 意思为这个神经元的输出结果为1, 即当以上神经元输入时,对应的这个神经元的sample_out的预测结果为1(100%)
for i in range(len(valideteset_samples)):
sample, sample_out = valideteset_samples[i] #sample对应读取的图像结果, sample_out对应结果为哪个数字
for xi in range(32):
for yi in range(32):
validate_x[i, xi, yi, 0] = sample[xi, yi] #校验集输入, i对应目前是哪个神经元的输入, sample为读取图像的结果
validate_y[i, sample_out] = 1 #校验集输出, 意思为这个神经元的输出结果为1, 即当以上神经元输入时,对应的这个神经元的sample_out的预测结果为1(100%)
input = keras.Input(shape=(32,32,1)) #输入层,32*32个神经元输入,一个输入通道,因为只是一个二维的黑白图像,一个输入通道即可。复杂的情况则需要多个输入通道,可以自己看看别的例子
layer = keras.layers.Conv2D(filters=32, kernel_size=(5,5), activation='relu')(input) #卷积层,5*5个神经元感受视野,32个卷积核,激励函数relu做非线性映射
layer = keras.layers.Conv2D(filters=8, kernel_size=(5,5), activation='relu')(layer) #卷积层,5*5个神经元感受视野,8个卷积核,激励函数relu做非线性映射
layer = keras.layers.MaxPool2D(pool_size=(2, 2))(layer) #池化层,maxpool取“池化视野”矩阵中的最大值,当输入经过卷积层时,得到的feature map (特征图)还是比较大,可以通过池化层来对每一个 feature map 进行降维操作
layer = keras.layers.Dropout(rate=0.4)(layer) #该层的作用相当于对参数进行正则化来防止模型过拟合
layer = keras.layers.Flatten()(layer) #将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。
layer = keras.layers.Dense(128, activation='relu')(layer) #全连接层,有128个神经元,激活函数采用‘relu’
layer = keras.layers.Dense(10, activation='softmax')(layer) #输出层,有10个神经元,每个神经元对应一个类别,输出值表示样本属于该类别的概率大小。
model = keras.Model(input, layer) #创建模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) #指定一些参数
print("training.....")
model.fit(x=x, y=y, batch_size=200, epochs=40, validation_data=(validate_x, validate_y)) #训练模型
model.save('C:/Users/bfs/Desktop/learning_ai/pictrue_model.h5')
return model
def verify_modle():
m_model = keras.models.load_model('C:/Users/bfs/Desktop/learning_ai/pictrue_model'+'.h5')
verify_sample = read_sample('C:/Users/bfs/Desktop/learning_ai/3.png') #我这里随便使用一张图片来进行实际预测
test_x = numpy.zeros((1, 32, 32, 1))
for xi in range(32):
for yi in range(32):
test_x[0, xi, yi, 0] = verify_sample[xi, yi]
predict_result = m_model.predict(x=test_x) #导入实际使用时的图片数据
ret = 0
max_prob = max(predict_result[0]) #返回最大的概率。训练结果是一个二维数组,相当于一列0-9的概率。最大的概率则为预测结果
for x in range(10):
if max_prob == predict_result[0, x]:
ret = x
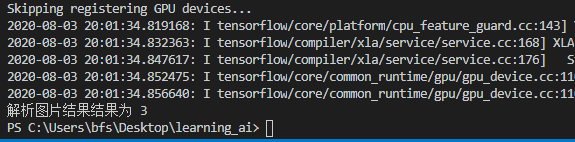
print('解析图片结果结果为', ret)
if __name__ == "__main__":
# train()
verify_modle()
|



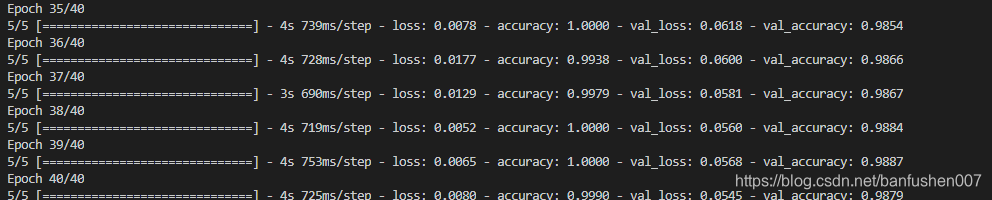 可以看到校验集的校验结果精确度达到98.8%左右
可以看到校验集的校验结果精确度达到98.8%左右