在k8s中,是不能够直接启动容器的,容器必须要依附于pod的形式启动。当pod启动失败的时候,可以这么去调试。
1.找到pod启动的镜像,将镜像进行二次封装,修改镜像的入口
1 | FROM xxxxx //pod启动的镜像 |
2.将镜像上传到镜像库
3.修改pod的yaml文件,修改镜像地址,修改探针
1 | containers: |
4.使用kubectl exec -it -n
在k8s中,是不能够直接启动容器的,容器必须要依附于pod的形式启动。当pod启动失败的时候,可以这么去调试。
1.找到pod启动的镜像,将镜像进行二次封装,修改镜像的入口
1 | FROM xxxxx //pod启动的镜像 |
2.将镜像上传到镜像库
3.修改pod的yaml文件,修改镜像地址,修改探针
1 | containers: |
4.使用kubectl exec -it -n
工作中,需要在k8s中调试container,但是container中有可能很多东西又没有,比如vim等,没有就无法修改代码,想使用su 更改为root用户又不知道密码。可以使用以下方法。
直接修改pod的yaml文件
1 | containers: |
这样登录进去就是root角色,0指root用户的uid。在里面就可以安装自己想安装的工具进行调试。
比如我,进去调试之后安装了vim
1 | apt update |
上一篇分析之后,本来第二部分分析是想分析start之后的逻辑的,这样会让人比较快速的理解skynet框架。但想想还是顺着代码启动的思路写下去会比较好,我觉得这样我自己更容易理解。
bootstrap是引导程序的意思,在skynet中,的确也是做了服务器工作的前置任务。
再skynet_start.c中
1 | //启动logger服务 |
查询配置
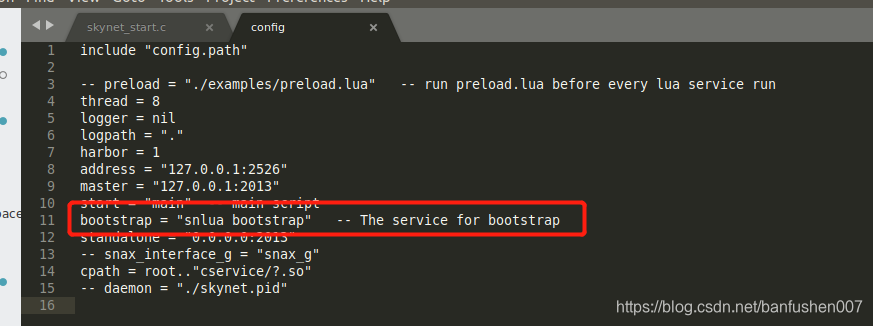
可以得知,传入的参数是”snlua bootsrtap”,再看到函数的实现
1 | static void |
接下来看到skynet_context_new方法,在skynet_server.c
1 | struct skynet_context * |
按照分析1、分析2的顺序。先看到skynet_module_instance_create,分析1
1 | void * |
看到snlua的create,再service_snlua.c,构建新的lua虚拟机,所以有服务之间的隔离。
1 | struct snlua * |
创建完虚拟机后,看到分析2,到skynet_module_instance_init,在skynet_module.c中,可以看到,其实就是上面代码注释说的,使用snlua的init去启动bootstarp
1 | int |
接下来我们到service_snlua.lua中看是怎么使用snlua去启动一个lua脚本的,skynet中,C模块的定义,必须要有一些方法,比如init,上面的m->init,最后会调用到下面的函数
1 | int |
发送消息后,调用到luanch_cb
1 | static int |
最后调用init_cb,下面是精简了的代码,只是为了说明调用流程
1 | static int |
启动了bootstrap又怎样呢,往下看bootstrap.lua
1 | skynet.start(function() |
看到skynet.newservice,这个在skynet中,就是lua层用来启动新服务的。在skynet.lua中,可以看到,call .launcher就是使用上面启动的launcher.lua去启动一个服务
1 | function skynet.newservice(name, ...) |
在看到launcher中的LAUNCH,在launcher.lua中
1 | require "skynet.manager" -- import manager apis |
下面看到skyne.launch,在manager.lua
1 | local c = require "skynet.core" |
调用到c.command,
这里的skynet.core是一个C语言模块,至此,我们将进入C语言实现部分,调用skynet.core.command(“LAUNCH”, “snlua …”)。
我们先总结一下lua部分的内容:
newservice–>skynet.call .launcher–>.launcher=skynet.launch(“snlua”, “launcher”)–>skynet.core.command(“LAUNCH”, “snlua …”)
skynet.core其实是在lua_skynet.c中定义的,其command对应于lcommand函数。 这时的参数其实都压进了lua_State中。
1 | static int |
也就最后调用到skynet_server.c中skynet_command
1 | static struct command_func cmd_funcs[] = { |
再看到cmd_launch,这里就十分熟悉了,接入回上面的bootstrap的分析
1 | static const char * |
可以看到,之后我们在lua层使用的skynet.newservice都是通过launcher.lua去启动新服务器的了。
最后bootstrap做的事情中一个重要就是,启动了launcher.lua服务,之后框架中skynet.newservice就是调用launcher去启动lua服务。
所以叫他服务器的前置任务。之后的启动新服务之后,回调函数怎么挂钩之类的,之后在分析。
下一篇分享bootstrap后skynet_start做了什么
在新公司中,开发是需要连接到开发机上的,而且员工作为普通用户,无法安装软件到除用户目录以外的目录(也就是没有root权限)。当我们需要下载安装一些常用工具时,因为没网,所以无法使用apt-get等下载指令。
ps:为什么没有root,就无法使用apt-get,因为apt-get是会去写一些文件到root用户才有权限的文件夹(例如/user….)或者修改系统环境变量的。而普通用户是没有权限,所以没法使用。
** 要解决这个问题,最主要的方法就是,修改安装的目录,添加自己用户下指定目录为环境变量。**
最后使用以下方法安装tmux,亲测可行。
这里有一个坑,待会儿说。
1 | wget -c https://github.com/tmux/tmux/releases/download/3.0a/tmux-3.0a.tar.gz |
tar -zxvf xxxxxx
1 | # libevent |
这里,如果出现类似这种错误,就是我上面说的坑。我自己也碰到了,最后改了过来,这个图是引用网上的,我的情况忘记截图了。
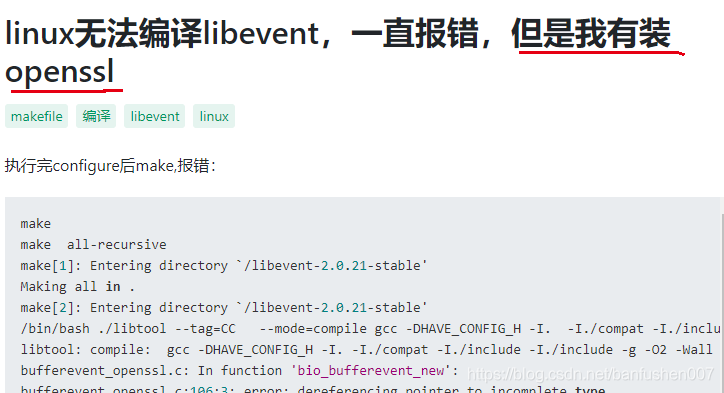
看这位的回答就知道原因了,原地址在https://segmentfault.com/q/1010000015949611
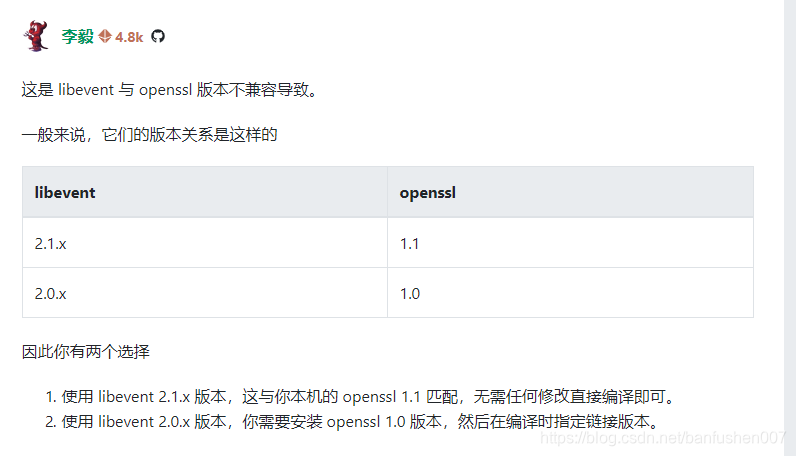
我选了相应版本后,解决了以上问题。最后安装成功。
最后设置环境变量
1 | #环境变量设置 |
使用skynet一年半了。源码也断断续续读了不少,也看了几篇skynet的源码分析。他们都说的很好。但是觉得分析只是给你一个理解代码的观点,但是没个人的理解方式是不一样的,我也写一写我自己的理解。
下面进入正题。
首先,还是要有一个观念,skynet是干嘛的,云风前辈的Skynet 设计综述,wiki什么的都是要读的。然后进入正题。
从我学习开始,我理解的一个C/C++程序都是从main函数开始运行的,skynet也不例外。以下的代码关键部分都带有注释。
**skynet_main.c **
main函数其实就是,解析配置,做一些初始化,然后使用配置去调用启动函数。
1 | int |
skynet_start.c
skynet_start做的就是继续初始化,这里需要注意的是bootstrap,这里通过配置可以知道,其实是启动的是snlua(用C写的模块),之后所有的lua服务都是通过snlua启动的(snlua加载lua文件))先记着,之后再分析。
1 | void |
然后调用,start,这是整个逻辑的启动,下篇先分析bootstrap。
昨天更新后,一直触发这个报错。第一眼看我都吓懵了,这什么鬼报错,call fail。框架级别的报错。这怎么解决。
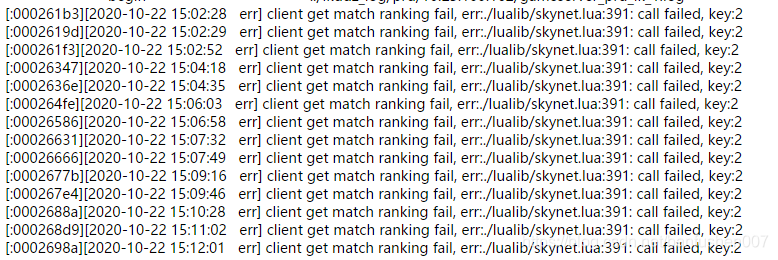
理性分析,然后在同事的提醒下查看了core的日志,然后发现
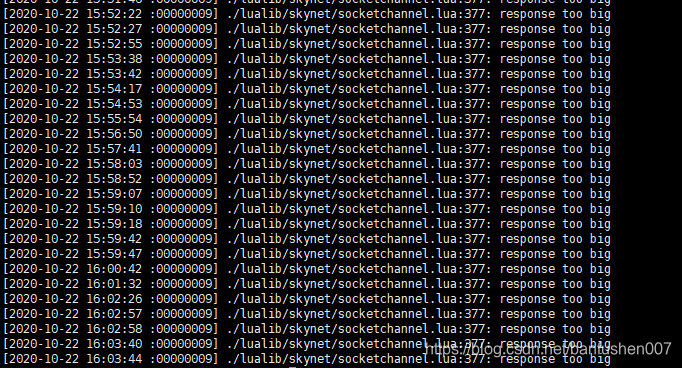
一查代码,发现
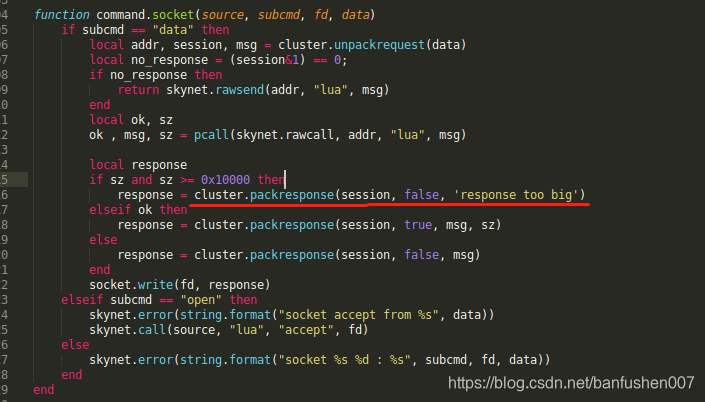
原来是集群通信中,传递的包过大造成的。获取玩家排行榜历史的时候,我缓存的所有玩家的历史,这样每个玩家只需要去拿就行了,不需要再进行多余的db操作。检查自己的逻辑,的确是发了很大的包。测试的时候数据不足,并没有发现。
想起在云风的blog中也说过,集群通信有错误会提示,但是业务层面要自己重新处理。
最后修改业务层面的代码解决,其实也可以把过大的包拆成几分发送。
用了很久lua,框架原因,今天写一下lua调用so库。
真的是不做不知道,一做真奇妙。网上那么多篇文章,基本上都是你抄我,我抄你。错误都一样,验证都没验证过。。。
先声明一下我的环境,Ubuntu 18.04,lua5.3
1.概念补充,lua和c交互是通过一个虚拟的栈来交互的,为什么是这样?
C与Lua之间通信关键内容在于一个虚拟的栈。几乎所有的调用都是对栈上的值进行操作,所有C与Lua之间的数据交换也都通过这个栈来完成。另外,也可以使用栈来保存临时变量。每一个与Lua通信的C函数都有其独有的虚拟栈,虚拟栈由Lua管理。
栈的使用解决了C和Lua之间两个不协调的问题:第一,Lua会自动进行垃圾收集,而C要求显式的分配存储单元,两者引起的矛盾。第二,Lua中的动态类型和C中的静态类型不一致引起的混乱。
2.要想调用C中的方法,则需要把C编译成动态库,我是在linux下,所以是.so,代码如下
c_so.cpp
1 | extern "C" { |
然后编译 gcc -shared -fPIC c_so.cpp -o mylib.so -I /home/lk/my_skynet_learning/skynet/3rd/lua/
编译完成后将会得到mylib.so

testso.lua
1 | local mylib = require "mylib" |
运行结果如下
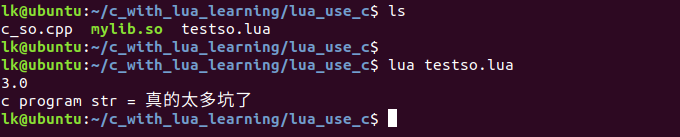
网上搜的真的是各种坑。哎。
随着业务的熟悉,也多出更多的时间在注意技术。碰到了一下问题,做一下记录。
1.怎么查看服务器当前的网络状态,怎么看socket是否断开,怎么查看各个端口的连接情况。
使用 ifconfig 用来显示所有网络接口的详细情况的,如:ip地址,子网掩码等。
使用 **netstat -na **显示当前网络各个端口连接信息,会显示各个连接的状态(a所有,n显示地址,可以加t指定tcp,l指定显示监听的套接字)。
2.linux fd(文件描述符)复用时怎么确保不出错。
3.客户端怎么异步的去连接服务器。
使用多线程或者多进程去连接服务器(线程池)
4.怎么查找一个目录和多个目录下含有指定输出的文件
使用 grep ‘xxxx’ [目录1] [目录2] -rn,查找目录1,目录2中出现 ‘xxxx’ 的文件,并显示出现在第几行。
5.skynet 不小心再 for 循环中使用了 call,另一个服务没有处理,这种情况怎么解决。
6.lua的table是怎么实现的。
这个我还没有看过,只知道 lua 的 table 是数组和hash一起实现的。有一个有意思的事情是,有一个 table ,table[1000] = 1,这种情况下是数组还是hash(虽然在我们看来是数组,但是实际上却是hash,简单的想,如果是数组也不实际,创建1000个地址,只存贮一个地址)。table 的 取长度,会查找一个整形的key,达成条件
table[key] != nil
table[key+1] == nil
所以,如果中间含有nil的table,计算长度,会出错。
7.怎么判断服务器是否发生死循环。
top:找出占用cpu过高的程序
top -H -p:记录下占用cpu的线程号
**gdb attach <进程号>**: 对占用cpu过高的程序进行gdb调试
info thread : 列出线程状态
thread <线程号> : 根据线程号切换到某个线程
bt : 输出堆栈
l : 查看当前代码
print <变量名> :输出必要的变量内容
detach:分离线程
q 退出gdb调试
处理死循环,重启进程/线程。
8.怎么查看自己的服务器到底能够承载多少人。
查看linux服务器的内存,查看一个玩家需要多少内存,进行计算。
9.socket write的时候,对方如果关闭了,内核缓冲区又还没满,尝试继续写会怎样。
先写入缓冲区,再写得话会返回错误,触发信号。
10.动态库静态库那个效率高。C++动态库为什么要声明 extern c。调用动态库的方法。
当程序与静态库连接时,库中目标文件所含的所有将被程序使用的函数的机器码被 copy 到最终的可执行文件中。这就会导致最终生成的可执行代码量相对变多,相当于编译器将代码补充完整了,优点,这样运行起来相对就快些。不过会有个缺点: 占用磁盘和内存空间. 静态库会被添加到和它连接的每个程序中, 而且这些程序运行时, 都会被加载到内存中. 无形中又多消耗了更多的内存空间。
与共享库连接的可执行文件只包含它需要的函数的引用表,而不是所有的函数代码,只有在程序执行时, 那些需要的函数代码才被拷贝到内存中。优点,这样就使可执行文件比较小, 节省磁盘空间,更进一步,操作系统使用虚拟内存,使得一份共享库驻留在内存中被多个程序使用,也同时节约了内存。缺点,不过由于运行时要去链接库会花费一定的时间,执行速度相对会慢一些,总的来说静态库是牺牲了空间效率,换取了时间效率,共享库是牺牲了时间效率换取了空间效率,没有好与坏的区别,只看具体需要了。
另外,一个程序编好后,有时需要做一些修改和优化,如果我们要修改的刚好是库函数的话,在接口不变的前提下,使用共享库的程序只需要将共享库重新编译就可以了,而使用静态库的程序则需要将静态库重新编译好后,将程序再重新编译一便。这也是使用过程当中的差别,以现在的项目举例,在远程更新的时候,如果只是*.so动态库封装内容变化了,那么只需要更新*.so即可。
被extern “C”修饰的变量和函数是按照C语言方式进行编译和链接的
11.skynet 使用的 epoll是什么模式,epoll 的水平触发和边缘触发有什么区别
水平触发(Level_triggered****),epoll默认是水平触发的,skynet没做修改。
水平触发(Level_triggered****):对于socket读来说,文件描述符关联的读内核缓冲区非空,有数据可以读取,就会触发读就绪,对于socket写来说,描述符关联的内核写缓冲区不满,就可以触发写就绪。
边缘触发(Edge_triggered):对于socket读来说,一旦有消息达到,触发一次读就绪,如果一次没有读完缓冲区,则剩余的消息将会留在缓冲区,不会触发读就绪。对于socket写来说,只触发一次写就绪,如果写满了缓冲区,当缓冲区发送完毕时,会再触发一次写就绪。如果未满,则也不会触发写就绪。
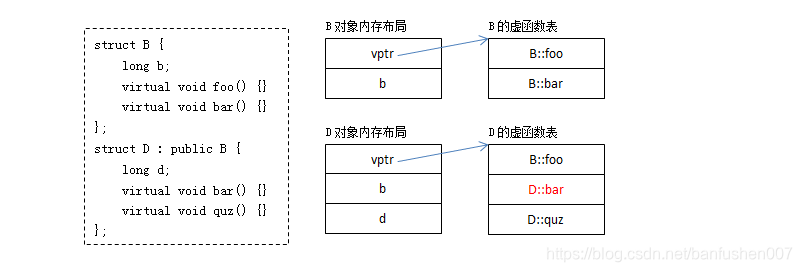
12.C++虚函数怎么实现的。
带有虚函数的类,编译器会为其额外分配一个虚函数表,里面记录的使虚函数的地址,当此类被继承时,子类如果也写了虚函数就在子类的虚函数表中将父类的函数地址覆盖,否则继承父类的虚函数地址。
实例化之后,对象有一个虚函数指针,虚函数指针指向虚函数表,这样程序运行的时候,通过虚函数指针找到的虚函数表就是根据对象的类型来指向的了。
13.skynet定时器是怎么实现的。
在刚开始使用skynet的时候,就已经知道call方法会挂起。但是一直到今天,都无法深刻理解这个挂起的意思。直到碰到了这个问题。解决后做此记录。
1.先描述一下出现的情况。
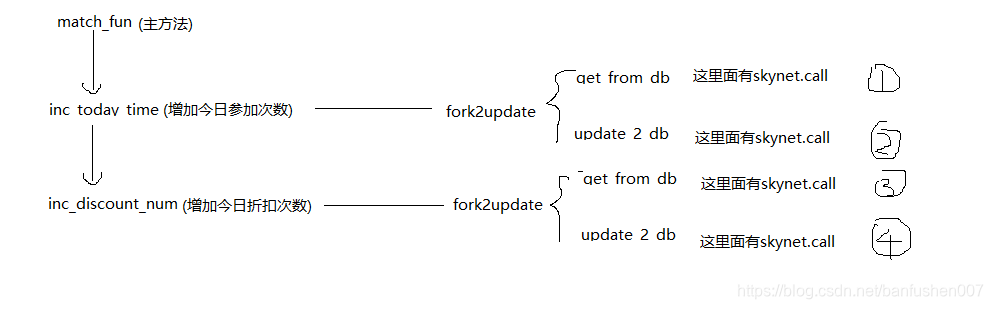
先暂且不管为什么要对db进行这么多次操作(原因太多)。在这个需求下,我本是想执行顺序为 1234,但是实际上确时1324。这会导致3拿到的是2更新之前的数据。今日参加次数就会在执行4的时候,没有能更新到2更新的内容。
2.为什么会出现这样的情况呢。
首先要了解 lua协程。在任一指定时刻只有一个协同程序在运行,并且这个正在运行的协同程序只有在明确的被要求挂起的时候才会被挂起。一般使用协程的时候,因为cpu的性能问题,会让我们感觉和多线程差不多。但是重点就是,同一时刻,只有一个协程在运行,而且在他让出cpu的时候,cpu才回去处理别的协程。
在上面的情况下,就是因为在步骤1的时候,调用了skynet.call。这个东西会挂起协程,也就是让出cpu。然后cpu就是处理了下面的协程,所以先调用了3。
3.怎么处理
有两个方法:a.修改业务,将这两个增加写到一起。
b.使用消息队列,skynet.queue。(代码很简单,就几行,即处理完当前协程的方法再调用下一个协程的方法)(云风前辈在blog也写过,skynet.queue,就是用来处理这了多协程,又要保证次序的问题。)
4.处理的注意事项,使用skynet.queue的时候,一定要确保丢进队列的顺序是1234,我自己就因为没有能很好的理解call的挂起,让上面两个协程分别把方法丢到队列里(再次踩坑,加深理解),最后丢进去的顺序又是1324。。。。查了好久,才找到。再次提醒,skynet.call会挂起协程。其实再很多游戏业务中,也会有这种场景,需要多注意。(如果是关于重要数据的修改,麻烦就大了,例如金币变动等)
5.虽然从技术上也解决了,但是最后我是修改了逻辑,将两个方法写成一个。没必要进行四次DB操作。但是这次的确也加深了我对协程挂起的理解。
最近被问到一个问题,什么是lua表的弱引用,之前看过lua程序设计第四版,但是当时不记得了,并不能回答出来。之后做了简单查阅,作此记录。
lua的垃圾回收机制是,当一个变量不再被引用了。当触发垃圾回收机制的时候,会回收这部分内存。而弱引用,则是更好的回收内存的一种方法。下面上代码:
对key设置弱引用之前:
1 | local t = {} |
输出结果是这样的:

可以看到,即使我们的表key1置为空了,但是表t依然能够打印出来(是表 t 还是包含着对表 key1 的引用)。下面我们设置key的弱引用,代码如下:
1 | local t = {} |
输出结果是这样的:

可以看到,当触发垃圾回收的时候,表t 已经被清空了。这就是由于对 table key 的弱引用,当key值没有被别的值引用时,垃圾回收会直接回收含有这个指定key的表的内存。
** 弱引用也可以设置位 table 的 value**。
** 对value设置弱引用之前:**
1 | local t = {} |
结果如下:

** 对value设置弱引用:**
1 | local t = {} |
结果如下:

也可以同时设置对 key 和 value 的弱引用。这样一旦有一个被置为nil,则垃圾回收时直接触发回收。
1 | local t = {} |
** 结果如下:**
** **最后,合理的使用弱引用,可以加强垃圾回收。但是如果不熟悉,也可能造成意想不到的后果。