你好,这里是拼图收集者。
这个博客会记录一些和技术相关的内容,主要包括:
- Linux
- Golang
- Lua
- Python
- Node.js
- Kubernetes
- Redis
先把站搭起来,后面再慢慢填坑。
你好,这里是拼图收集者。
这个博客会记录一些和技术相关的内容,主要包括:
先把站搭起来,后面再慢慢填坑。
top -P pid,其中RSS为进程当前使用的内存
1 | top - 22:18:50 up 163 days, 5:48, 64 users, load average: 0.88, 1.07, 1.45 |
cat /proc/pid/status其中VMRSS为进程使用内存
1 | banfushen@ma100:~/$ cat /proc/1696650/status |
sudo apt-get install redis-server
ps -aux | grep redis
sudo subl /etc/redis/redis.conf,改为自己想要的端口。
sudo service redis-server restartps -aux | grep redis
继续修改/etc/redis/redis.conf,找到一个 # requirepass foobared 的字段将这个字段的注释取消掉,这个字段是数据的访问密码,将foobared替换成自己想要设置的密码。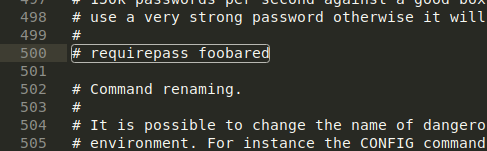
修改后重启redis,sudo service redis-server restart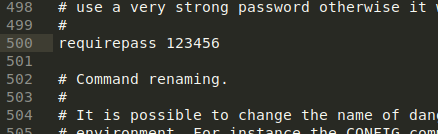
sbul是我装了sublime text之后的编辑器,如果没有安装,将subl换成vi/vim即可。我自己通过以上方式,已能修改,做次记录。
项目上线后,通过kubectl top node,发现有的node上使用的资源非常少,kubectl describe node 发现完全可以驱逐。但是cluster autoscaler缺没有驱逐。
Perf是用于软件性能分析的工具,通过Perf,应用程序可以利用PMU,tracepoint和内核中的特殊计数器进行性能统计。Perf不但可以分析应用程序的性能问题(per thread),也可以分析内核的性能问题,处理所有性能相关的事件:程序运行期间的硬件事件,如instructions retired ,processor clock cycles等;软件事件,如Page Fault和进程切换。
Perf基本原理是对被监测对象进行采样,最简单的情形是根据tick中断进行采样,即在tick中断内触发采样点,在采样点里判断程序当前的上下文。假如一个程序90%的时间都花费在函数func1()上,那么90%的采样点都应该落在函数func1()的上下文中,采样时间越长,上述推论越可靠。使用perf要有管理员权限
在此程序中,创建了两个线程。分别跑了不同次数的func1()方法。gcc -lpthread main.c
1 |
|
1 | root@ma100:/home/banfushen/perf_cpu/multi_thread# perf record -h |
perf record -g -F 99 ./a.out,对多线程程序进行采样,采样频率99,(-F 99: sample at 99 Hertz (samples per second). I’ll sometimes sample faster than this (up to 999 Hertz), but that also costs overhead. 99 Hertz should be negligible. Also, the value ‘99’ and not ‘100’ is to avoid lockstep sampling, which can produce skewed results.)。运行完毕会得到一个perf.data,要想得到火焰图,还需要借助别的工具。
对于已经启动的程序,要拿到pid,perf record -g -F 99 -p <pid>
git clone https://github.com/brendangregg/FlameGraph.git
1 | banfushen@ma100:~/perf_cpu/FlameGraph$ pwd |
perf script |/home/banfushen/perf_cpu/FlameGraph/stackcollapse-perf.pl|/home/banfushen/perf_cpu/FlameGraph/flamegraph.pl > output.svg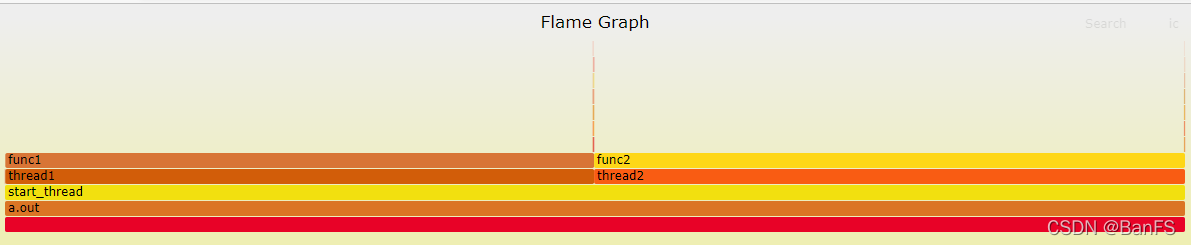
要知道线程id
1 | root@ma100:/home/banfushen/perf_cpu/multi_thread# perf script -h |
perf script -v --tid <tid> 指定线程perf script -v --tid 2283471|/home/banfushen/perf_cpu/FlameGraph/stackcollapse-perf.pl|/home/banfushen/perf_cpu/FlameGraph/flamegraph.pl > output1.svg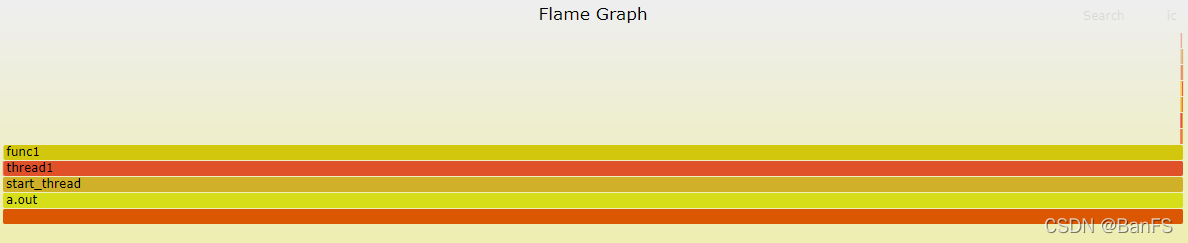
perf script -v --tid <tid[,tid...]> 指定多个线程perf script -v --tid 2283472,2283471|/home/banfushen/perf_cpu/FlameGraph/stackcollapse-perf.pl|/home/banfushen/perf_cpu/FlameGraph/flamegraph.pl > output3.svg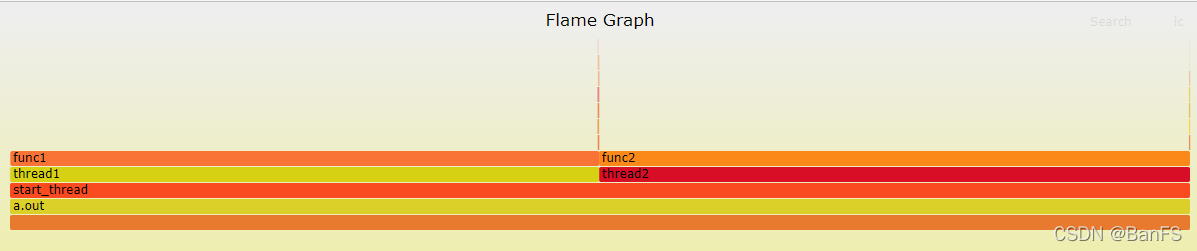
参考资料:
perf Examples
perf性能分析
性能分析利器之perf浅析
利用perf剖析Linux应用程序
Linux性能分析工具Perf简介
在项目中,需要用lua脚本操作redis cluster中的多个key,但是非同slot的时候会报错,例如下面test3、test6在同一个node,但是却不是同一个slot。redis使用lua脚本可以这样redis-cli -a xxxxx--eval demo.lua key1 key2 , val1 val2
1 | banfushen@ma100:~/redis-cluster$ redis-cli -p 16380 -c |
一般在redis cluster中使用lua脚本,会碰到(error) CROSSSLOT Keys in request don't hash to the same slot
1 | banfushen@ma100:~/test$ cat get.lua |
在官方的说明中,redis 使用lua脚本是限制在用一个node上使用的,可是这里明明是同一个node,却无法使用,但是如果我们把脚本改成下面这样
1 | banfushen@ma100:~/test$ cat get.lua |
这样即可解决。
应该是按照KEY传入的时候,redis为了防止key不在同一个node上,对key进行slot判断,如果不是同一个slot就直接返回了,但是是支持同一个node的,只要我们对我们需要操作的key进行分类,同一个node的key通过value传入,即可在lua脚本中对同一个node的key操作。在我们设计redis cluster的时候,是知道每个node的slot的,每个key的solt可以使用以下计算
1 | 192.168.88.3:6379> cluster keyslot test3 |
我们只需要先判断slot在某个范围内,属于一个node,即可进行批量操作。
redis-cli -p xxxx -c cluster nodes
perf可以针对进程进行profile,也可以对线程进行profile。再对进程profile之后,拿到perf.data,也可以修改为针对进程下的线程进行profile。所以照理来说应该是可以从perf.data中查看到有多少线程。
这也符合我们的一般要求,即有perf.data之后,可以针对线程显示火焰图。经过查询资料发现,perf中有perf data convert --force --to-json temp.json可以把perf.data转成json进行查看,但是要新版本的perf才有…这就恨坑爹,以为着我们需要自己安装最新的perf。
我的系统是RedHat系列,对应的Debian系列需要自己修改一下install相关。
拉取最新的内核代码git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git --depth 1000
1 | [root@ip-10-155-128-114 ~]# cd linux/tools/perf/ |
错误原因是没有flex,安装flex,yum install flex,安装flex之后还需要安装bison,yum install bison,安装完毕后重新LIBBABELTRACE=1 LIBBABELTRACE_DIR=/usr/local make即可,前面加环境变量是因为需要在这个环境变量下编译才能使用perf data做转换。否则会报错perf should be compiled with environment variables LIBBABELTRACE=1 and LIBBA。
之后便可以用perf data将采集到的数据转成json,这样就可以看到进程中有哪些线程,可以针对单线程做profile。
1 | [root@ip-10-155-136-104 ~]# ./linux/tools/perf/perf record -g -F 99 -p 3169 ## 3169是进程id |
最后在写个脚本分析json文件即可。
参考:
perf.data转成json。
perf file format
perf.data-file-format.txt
项目集群是使用k8s管理的,流量分发使用的是iptable,据压测反馈说负载不均衡,吓得老夫赶紧去查看,发现原来是压测同学搞错了。在查询的过程中,发现iptable规则之后的probability越来越大,记录一下原因。
1 | root@ip-10-1-34-89:/home/admin# iptables -t nat -nL |
可以看到,总共5条记录,刚开始probability为0.2—->0.25—->0.33—->0.5—-无,为什么会这样。
因为流量进入之后,按照iptable规则转发,公共5条,所以第一条接收20%的流量。
剩下还有4条,下一条应该接收剩余流量的1/4,也就是25%。
剩下还有3条,下一条应该接收剩余流量的1/3,也就是33%。
……
最后一条因为只剩下它了,所有流量都会走这里,所以不用写probability。