回家的路上看了一下cpu的结构,想起了前两天和领导吃饭时聊到的问题,为什么数组遍历比链表快,明明都知道地址了。
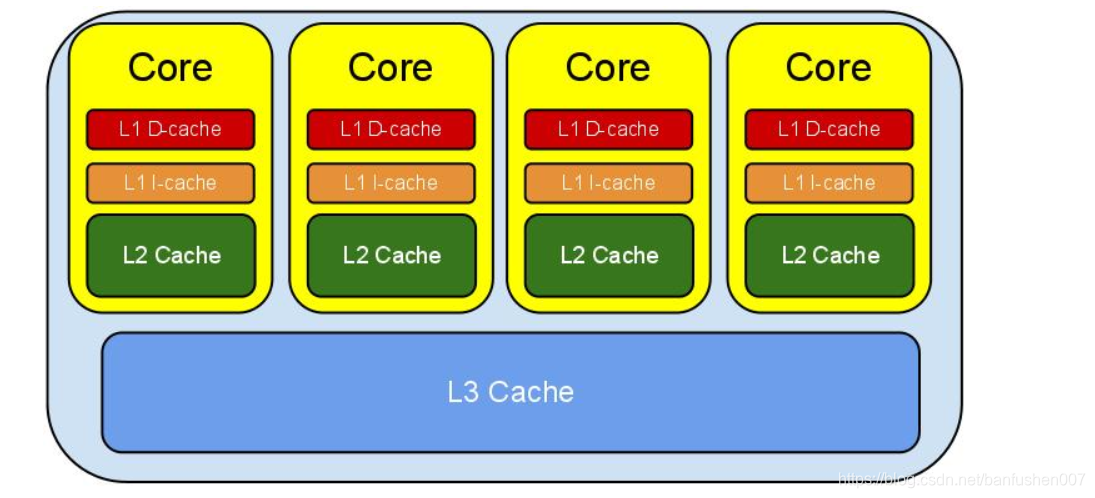
其实要理解这个问题,从cpu的结构和内存角度来理解就很清晰了。
读取速度:缓存>内存(剧吐多少倍差距,得看什么cpu,大概都有100倍左右)。
** **cpu读取数据是按照缓存行读取到缓存的,简单来说就是cpu会把需要的数据加载到缓存中,查找数据时,会先从缓存找,找不到再到内存找。
而数组作为连续内存,cpu缓存会把一片连续的内存空间读入,这样连续内存的数组会更易于整块读取到缓存中,当进行遍历时,直接命中缓存。而链表是跳跃式的地址,很轻易就会跳出缓存,跑到内存中去查找数据。所以会慢很多。
看下面的程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| #include <time.h>
#include <stdio.h>
void show_arr_addr(){
long arr[2][8];
for(int i=0; i<2; i++)
{
printf("row addr:%X\n", arr[i]);
printf("column addr: ");
for(int j=0; j<8; j++)
{
printf("%X, ", &arr[i][j]);
}
printf("\n");
}
}
int main() {
double start = 0, finish = 0;
long arr[100000][8];
show_arr_addr();
printf("---------------------------\n");
// 先遍历行,在遍历列
start=(double) clock();
for(int i=0; i<100000; i++)
for(int j=0; j<8; j++)
arr[i][j] = 1;
finish=(double)clock();
printf("use time:%.5f ms\n",finish-start);
// 先遍历列,再遍历行
start=(double) clock();
for(int j=0; j<8; j++)
for(int i=0; i<100000; i++)
arr[i][j] = 1;
finish=(double)clock();
printf("use time:%.5f ms\n",finish-start);
}
|
我是64位的cpu,所以cpu读取一次是按照64根总线,也就是64位。我构造了一个二维数组,每行是64位,可以看数组的地址,是连续的。
下面先进行遍历,两种遍历,先遍历列会跳出上次读取的缓存行。所以会比先遍历行慢。链表的道理也是一样,如果地址是存在缓存之外的,就会花费更多的时间。
